
Pyspark中的map方法运行失败问题
本文最后更新于 2024-07-04,文章内容可能已经过时。
问题说明:
在使用Pyspark模块中的map方法进行数据计算操作时,发现控制台疯狂报错,如图:
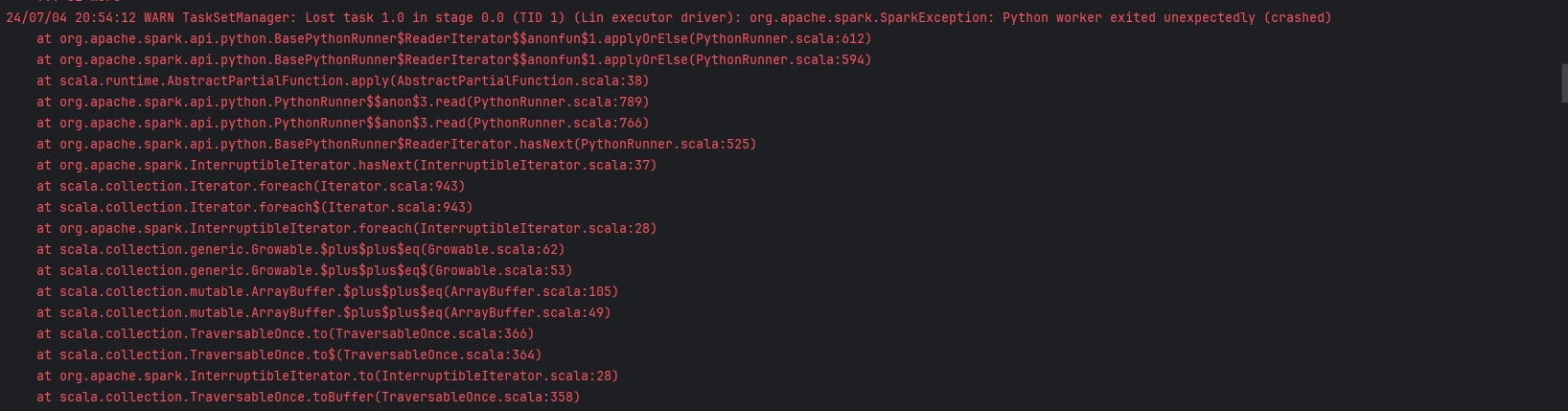
ps.运行代码如下
from pyspark import SparkConf, SparkContext
import os
# 确保PYSPARK_PYTHON指向正确的Python解释器路径
os.environ['PYSPARK_PYTHON'] = "E:/SoftWare/Python/python.exe"
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 基于SparkConf类对象创建SparkContext对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 定义计算函数
def func(data):
return data * 10
# 通过map方法进行数据计算
rdd2 = rdd.map(func)
print(rdd2.collect())
sc.stop()解决过程:
检查本机运行环境:
JDK:22Python:3.12
Pyspark:3.5.1
尝试询问AI得到如下回答:
Python 3.12目前并未正式支持PySpark,因为Apache Spark的官方推荐版本通常会落后于Python的最新稳定版。PySpark是为了让Spark能够在Python环境中运行而开发的库,它依赖于Spark的C/C++核心以及Python的API绑定。
切换Python版本为3.10(已知兼容性及稳定性目前为最佳)
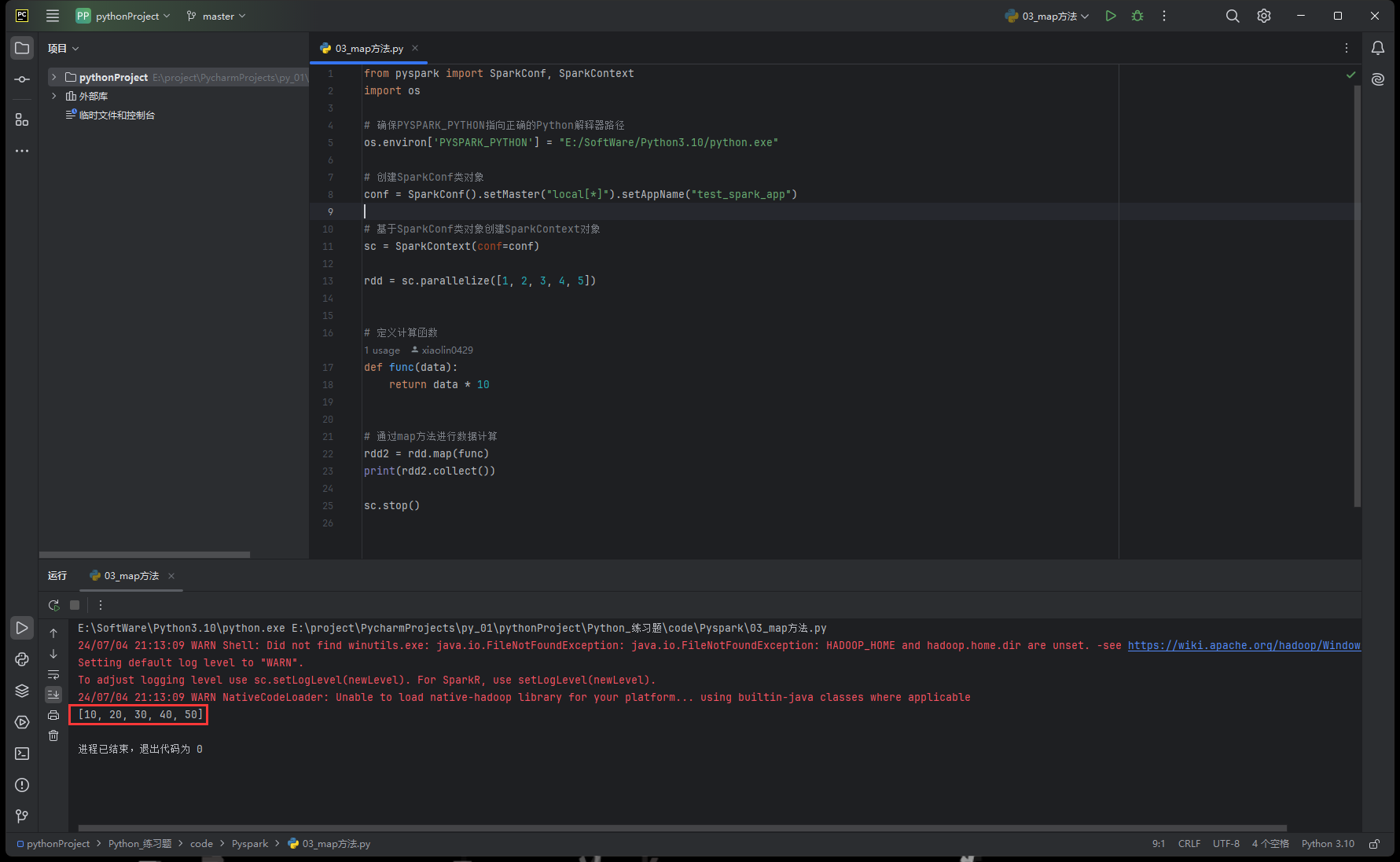
问题结果:
成功使用map方法输出对应计算结果
总结:
不要贸然使用最新版本的各类模块或者语言版本环境,模块与语言版本之间的兼容性可能会存在问题
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 Lin
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果